스레드를 직접 사용할 때의 문제점
- 스레드 생성 시간으로 인한 성능 문제
- 스레드 관리 문제
- Runnable 인터페이스의 불편함
1. 스레드 생성 비용으로 인한 성능 문제
스레드를 사용하려면 먼저 스레드를 생성해야 한다. 그런데 스레드는 다음과 같은 이유로 매우 무겁다.
메모리 할당 : 각 스레드는 자신만의 호출 스택(call stack)을 가지고 있어야 한다. 이 호출 스택은 스레드가 실행되는 동안 사용하는 메모리 공간이다. 따라서 스레드를 생성할 때는 이 호출 스택을 위한 메모리를 할당해야 한다.
운영체제 자원 사용 : 스레드를 생성하는 작업은 운영체제 커널 수준에서 이루어지며, 시스템 콜(system call)을 통해 처리된다. 이는 CPU와 메모리 리소스를 소모하는 작업이다.
운영체제 스케줄러 설정 : 새로운 스레드가 생성되면 운영체제의 스케줄러는 이 스레드를 관리하고 실행 순서를 조정해야 한다. 이는 운영체제의 스케줄링 알고리즘에 따라 추가적인 오버헤드가 발생할 수 있다.
예를 들어서 어떤 작업 하나를 수행할 때 마다 스레드를 각각 생성하고 실행한다면, 스레드의 생성 비용 때문에, 이미 많 은 시간이 소모된다. 아주 가벼운 작업이라면, 작업의 실행 시간보다 스레드의 생성 시간이 더 오래 걸릴 수도 있다 이런 문제를 해결하려면 생성한 스레드를 재사용하는 방법을 고려할 수 있다. 스레드를 재사용하면 처음 생성할 때를 제외하고는 생성을 위한 시간이 들지 않는다. 따라서 스레드가 아주 빠르게 작업을 수행할 수 있다.
2. 스레드 관리 문제
서버의 CPU, 메모리 자원은 한정되어 있기 때문에, 스레드는 무한하게 만들 수 없다. 예를 들어서, 사용자의 주문을 처리하는 서비스라고 가정하자. 그리고 사용자의 주문이 들어올 때 마다 스레드를 만들어 서 요청을 처리한다고 가정하겠다. 서비스 마케팅을 위해 선착순 할인 이벤트를 진행한다고 가정해보자. 그러면 사용자 가 갑자기 몰려들 수 있다. 평소 동시에 100개 정도의 스레드면 충분했는데, 갑자기 10000개의 스레드가 필요한 상황 이 된다면 CPU, 메모리 자원이 버티지 못할 것이다. 이런 문제를 해결하려면 우리 시스템이 버틸 수 있는, 최대 스레드의 수 까지만 스레드를 생성할 수 있게 관리해야 한다. 또한 이런 문제도 있다. 예를 들어 애플리케이션을 종료한다고 가정해보자. 이때 안전한 종료를 위해 실행 중인 스레드가 남은 작업은 모두 수행한 다음에 프로그램을 종료하고 싶다거나, 또는 급 하게 종료해야 해서 인터럽트 등의 신호를 주고 스레드를 종료하고 싶다고 가정해보자. 이런 경우에도 스레드가 어딘가에 관리가 되어 있어야한다.
3. Runnable 인터페이스의 불편함
반환 값이 없다: run() 메서드는 반환 값을 가지지 않는다. 따라서 실행 결과를 얻기 위해서는 별도의 메커니즘을 사용해야 한다. 쉽게 이야기해서 스레드의 실행 결과를 직접 받을 수 없다.
예외 처리: run() 메서드는 체크 예외(checked exception)를 던질 수 없다. 체크 예외의 처리는 메서드 내부에서 처리해야 한다.



이렇게 스레드 풀이라는 개념을 사용하면 스레드를 재사용할 수 있어서, 재사용시 스레드의 생성 시간을 절약할 수 있다. 그리고 스레드 풀에서 스레드가 관리되기 때문에 필요한 만큼만 스레드를 만들 수 있고, 또 관리할 수 있다.
이런 문제를 한방에 해결해주는 것이 바로 자바가 제공하는 Executor 프레임워크다.
Executor 프레임워크
public interface Executor {
void execute(Runnable command);
}
public interface ExecutorService extends Executor, AutoCloseable {
<T> Future<T> submit(Callable<T> task);
@Override
default void close(){...}
...
}반환 값이 있는 Runnable
public abstract class ExecutorUtils {
public static void printState(ExecutorService executorService) {
if (executorService instanceof ThreadPoolExecutor poolExecutor) {
int pool = poolExecutor.getPoolSize();
int active = poolExecutor.getActiveCount();
int queuedTasks = poolExecutor.getQueue().size();
long completedTask = poolExecutor.getCompletedTaskCount();
log("[pool=" + pool + ", active=" + active + ", queuedTasks=" + queuedTasks + ", completedTasks=" + completedTask + "]");
} else {
log(executorService);
}
}
}
- poll : 스레드 풀에서 관리되는 스레드의 숫자
- active : 작업을 수행하는 스레드의 숫자
- queuedTasks : 큐에 대기중인 작업의 숫자
- completedTask : 완료된 작업의 숫자
public class ExecutorBasicMain {
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(2, 2, 0,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
log("== 초기 상태 ==");
printState(es); //초기상태 출력 0,0,0,0이 나올 것임.
es.execute(new RunnableTask("taskA"));
es.execute(new RunnableTask("taskB"));
es.execute(new RunnableTask("taskC"));
es.execute(new RunnableTask("taskD"));
log("== 작업 수행 중 ==");
printState(es);
sleep(3000);
log("== 작업 수행 완료 ==");
printState(es);
es.close();
log("== shutdown 완료 ==");
printState(es);
}
}
12:33:00.483 [ main] == 초기 상태 ==
12:33:00.516 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=0]
12:33:00.519 [ main] == 작업 수행 중 ==
12:33:00.520 [ main] [pool=2, active=2, queuedTasks=2, completedTasks=0]
12:33:00.522 [pool-1-thread-2] taskB 시작
12:33:00.524 [pool-1-thread-1] taskA 시작
12:33:01.534 [pool-1-thread-1] taskA 완료
12:33:01.534 [pool-1-thread-2] taskB 완료
12:33:01.535 [pool-1-thread-1] taskC 시작
12:33:01.536 [pool-1-thread-2] taskD 시작
12:33:02.546 [pool-1-thread-2] taskD 완료
12:33:02.546 [pool-1-thread-1] taskC 완료
12:33:03.540 [ main] == 작업 수행 완료 ==
12:33:03.549 [ main] [pool=2, active=0, queuedTasks=0, completedTasks=4]
12:33:03.553 [ main] == shutdown 완료 ==
12:33:03.553 [ main] [pool=0, active=0, queuedTasks=0, completedTasks=4]

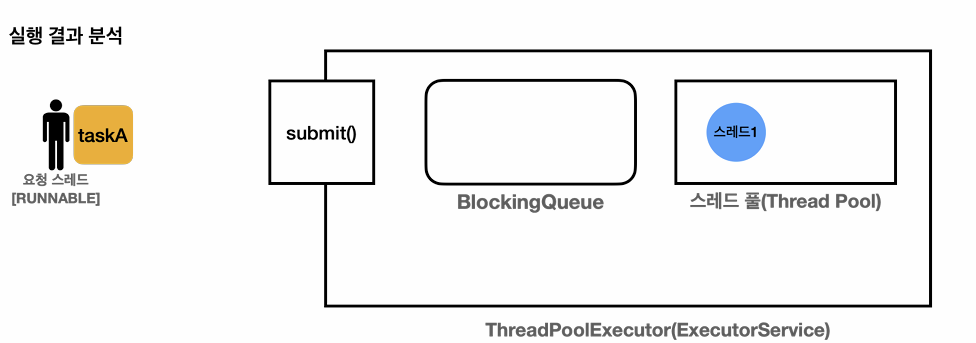
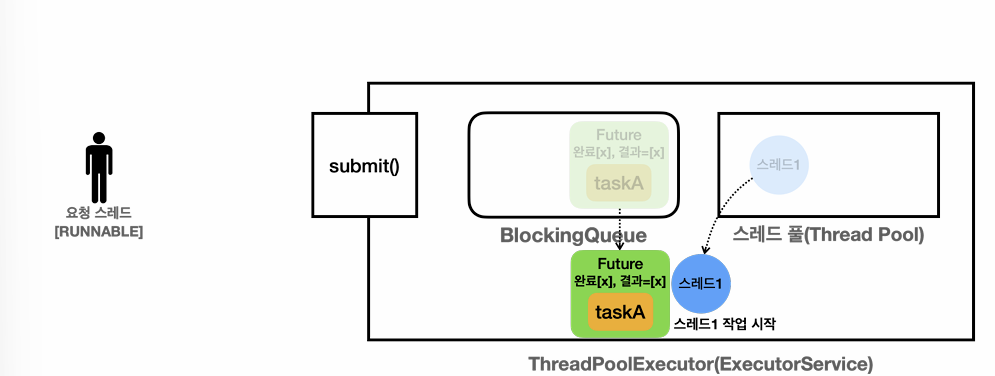
스레드 풀 : 스레드를 관리한다.
BlockingQueue : 작업을 보관한다. 생산자 소비자 문제를 해결하기 위해 사용하였다.
생산자: es.execute(작업) 를 호출하면 내부에서 BlockingQueue 에 작업을 보관한다. main thread가 생산자가 된다.
소비자 : 스레드 풀에 있는 스레드가 소비자이다. 이후에 소비자 중에 하나가 BlockingQueue 에 들어있는 작업을 받아서 처리한다.



public class CallableMainV1 {
public static void main(String[] args) throws ExecutionException,InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(1);
Future<Integer> future = es.submit(new MyCallable());
Integer result = future.get();
log("result value = " + result);
es.close();
}
static class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
log("Callable 시작");
sleep(2000);
int value = new Random().nextInt(10);
log("create value = " + value);
log("Callable 완료");
return value;
}
}
}
Executor 프레임워크의 강점
요청 스레드가 결과를 받아야 하는 상황이라면, Callable 을 사용한 방식은 Runnable 을 사용하는 방식보다 훨씬 편리하다. 코드만 보면 복잡한 멀티스레드를 사용한다는 느낌보다는, 단순한 싱글 스레드 방식으로 개발한다는 느낌이 들 것이다. ExecutorService 에 필요한 작업을 요청하고 결과를 받아서 쓰면 된다!
submit() 의 호출로 MyCallable 의 인스턴스를 전달한다. submit()은 MyCallable.call()이 반환하는 무작위 숫자 대신에 Future를 반환한다.


이전에 했던 sumTask 관련 코드를 수정하였다.
public class SumTask {
public static void main(String[] args) throws InterruptedException, ExecutionException {
SumTask task1 = new SumTask(1, 50);
SumTask task2 = new SumTask(51, 100);
ExecutorService es = Executors.newFixedThreadPool(2);
Future<Integer> future1 = es.submit(task1);
Future<Integer> future2 = es.submit(task2);
Integer sum1 = future1.get();
Integer sum2 = future2.get();
log("task1.result=" + sum1);
log("task2.result=" + sum2);
int sumAll = sum1 + sum2;
log("task1 + task2 = " + sumAll);
log("End");
es.close();
}
static class SumTask implements Callable<Integer> {
int startValue;
int endValue;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
public Integer call() throws InterruptedException {
log("작업 시작");
Thread.sleep(2000);
int sum = 0;
for (int i = startValue; i <= endValue; i++) {
sum += i;
}
log("작업 완료 result=" + sum);
return sum;
}
}
}미리 get으로 받아놔서 다음 것을 받을때 대기를 하지 않아도 된다.
마치 멀티스레드를 사용하지 않고, 단일 스레드 상황에서 일반적인 메서드를 호출하고 결과를 받는 것 처럼 느껴진다.


future1.get() 을 호출하며 대기한다. -> 작업 스레드1이 작업을 진행하는 약 2초간 대기하고 결과를 받는다.
이후에 요청 스레드는 future2.get() 을 호출하며 즉시 결과를 받는다. 작업 스레드2는 이미 2초간 작업을 완료했다. 따라서 future2.get() 은 거의 즉시 결과를 반환한다.
Future 는 요청 스레드를 블로킹(대기) 상태로 만들지 않고, 필요한 요청을 모두 수행할 수 있게 해준다. 필요한 모든 요청을 한 다음에 Future.get() 을 통해 블로킹 상태로 대기하며 결과를 받으면 된다. 이런 이유로 ExecutorService 는 결과를 직접 반환하지 않고, Future 를 반환한다.
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
enum State {
RUNNING,
SUCCESS,
FAILED,
CANCELLED
}
default State state() {}
}boolean cancel(boolean mayInterruptIfRunning) : 아직 완료되지 않은 작업을 취소한다. 실행중인 작업은 중단 X
취소: true , 취소X : false
boolean isCancelled() : 작업이 취소되었는지 여부를 확인한다. 취소: true , 취소X : false
boolean isDone() : 작업이 완료되었는지 (긍정 + 부정 여부 상관없이 그냥 끝났는지) 여부를 확인한다. 완료 : true, 완료X: false
V get() : 작업이 완료될 때까지 대기하고, 완료되면 결과를 반환한다. get 을 호출한 현재 스레드를 대기(블록킹)한다. 작업이 완료되면 결과를 반환한다.
public class FutureExceptionMain {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(1);
log("작업 전달");
Future<Integer> future = es.submit(new ExCallable());
sleep(1000); // 잠시 대기
try {
log("future.get() 호출 시도, future.state(): " + future.state());
Integer result = future.get();
log("result value = " + result);
}
catch (InterruptedException e) {
throw new RuntimeException(e);
}
catch (ExecutionException e) {
log("e = " + e);
Throwable cause = e.getCause(); // 원본 예외
log("cause = " + cause);
}
es.close();
}
static class ExCallable implements Callable<Integer> {
@Override
public Integer call() {
log("Callable 실행, 예외 발생");
throw new IllegalStateException("ex!");
}
}
}e.getCause() 을 호출하면 작업에서 발생한 원본 예외를 받을 수 있다.
'운영체제' 카테고리의 다른 글
| 스레드 풀과 Executor 프레임워크 - 2 (0) | 2024.12.21 |
|---|---|
| 원자적 연산 (2) | 2024.12.20 |
| 생산자 소비자 문제 (0) | 2024.12.18 |
| concurrent Lock (1) | 2024.12.16 |
| Synchronized (0) | 2024.12.15 |