원자적 연산
원자적 연산 (atomic operation)의 의미는 해당 연산이 더 이상 나눌 수 없는 단위로 수행된다는 것을 의미한다. 즉, 원자적 연산은 중단되지 않고, 다른 연산과 간섭 없이 완전히 실행되거나 전혀 실행되지 않는 성질을 가지고 있다. 쉽게 이야기해서 멀티스레드 상황에서 다른 스레드의 간섭 없이 안전하게 처리되는 연산이라는 뜻이다.
성질을 가지고 있다. 쉽게 이야기해서 멀티스레드 상황에서 다른 스레드의 간섭 없이 안전하게 처리되는 연산이라는 뜻 synchronized 블록이나 Lock 등을 사용해서 안전한 임계 영역을 만들어야 한다.
public interface IncrementInteger {
void increment();
int get();
}
public class BasicInteger implements IncrementInteger {
private int value;
@Override
public void increment() {
value++;
}
@Override
public int get() {
return value;
}
}
public class IncrementThreadMain {
public static final int THREAD_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
test(new BasicInteger());
}
private static void test(IncrementInteger incrementInteger) throws InterruptedException{
Runnable runnable = new Runnable() {
@Override
public void run() {
sleep(10); //너무 빨리 실행되기 때문에, 다른 스레드와 동시 실행을 위해 잠깐 쉬었다가 실행
incrementInteger.increment();
}
};
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < THREAD_COUNT; i++) {
Thread thread = new Thread(runnable);
threads.add(thread);
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
int result = incrementInteger.get();
System.out.println(incrementInteger.getClass().getSimpleName() + " result: " + result);
}
}
이 문제는 앞서 설명한 것 처럼 여러 스레드가 동시에 원자적이지 않은 value++을 호출 했기에 문제가 발생했다.
volatile 은 연산 차제를 원자적으로 묶어주는 기능이 아니다. 사용하면 CPU의 캐시 메모리를 무시하고, 메인 메모리를 직접 사용하도록 한다. 하지만 지금 이 문제는 캐시 메모리가 영향을 줄 수는 있지만, 캐시 메모리를 사용하지 않고, 메인 메모리를 직접 사용해도 여전히 발생하는 문제이다.
synchronized 블럭이나 Lock 등을 사용해서 안전한 임계 영역을 만들어야 한다.
public class SyncInteger implements IncrementInteger {
private int value;
@Override
public synchronized void increment() {
value++;
}
@Override
public synchronized int get() {
return value;
}
}
public static void main(String[] args) throws InterruptedException {
test(new BasicInteger());
test(new SyncInteger());
}synchronized 를 통해 안전한 임계 영역을 만들고 value++을 수행하니 1000이 나왔다. 안전하게 Thread가 value++연산을 수행한 것이다.
AtomicInteger 을 사용해서 SyncInteger 와 같이 멀티스레드 상황에서 안전하게 증가 연산을 수행할 수 있는 AtomicInteger라는 클래스를 제공한다.
public class MyAtomicInteger implements IncrementInteger {
AtomicInteger atomicInteger = new AtomicInteger(0);
@Override
public void increment() {
atomicInteger.incrementAndGet();
}
@Override
public int get() {
return atomicInteger.get();
}
}AtomicInteger 는 멀티스레드 상황에 안전하고 또 다양한 값 증가, 감소 연산을 제공한다. 특정 값을 증가하거나 감소해야 하는데 여러 스레드가 해당 값을 공유해야 한다면, AtomicInteger을 사용하면 된다.
속도 Test를 하니..
public class IncrementPerformanceMain {
public static final long COUNT = 100_000_000;
public static void main(String[] args) {
test(new BasicInteger());
test(new SyncInteger());
test(new MyAtomicInteger());
}
private static void test(IncrementInteger incrementInteger) {
long startMs = System.currentTimeMillis();
for (long i = 0; i < COUNT; i++) {
incrementInteger.increment();
}
long endMs = System.currentTimeMillis();
System.out.println(incrementInteger.getClass().getSimpleName() + ": ms="
+ (endMs - startMs));
}
}
BasicInteger: ms=40
SyncInteger: ms=2125
MyAtomicInteger: ms=832
AtomicInteger의 incrementAndGet() 메서드는 락을 사용하지 않고, 원자적 연산을 만들어 낸다.
락 기반 방식의 문제점
SyncInteger 와 같은 클래스는 데이터를 보호하기 위해 락을 사용한다. 락은 특정 자원을 보호하기 위해 스레드가 해당 자원에 대한 접근하는 것을 제한한다. 락이 걸려 있는 동안 다른 스레드 들은 해당 자원에 접근할 수 없고, 락이 해제될 때까지 대기해야 한다. 또한 락 기반 접근에서는 락을 획득하고 해제하는 데 시간이 소요된다.
보통은 LOCK을 쓰지만 종종 이런걸 사용할 수 있다.
public class CasMainV1 {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(0);
System.out.println("start value = " + atomicInteger.get());
boolean result1 = atomicInteger.compareAndSet(0, 1);
System.out.println("result1 = " + result1 + ", value = " + atomicInteger.get());
boolean result2 = atomicInteger.compareAndSet(0, 1);
System.out.println("result2 = " + result2 + ", value = " + atomicInteger.get());
}
}
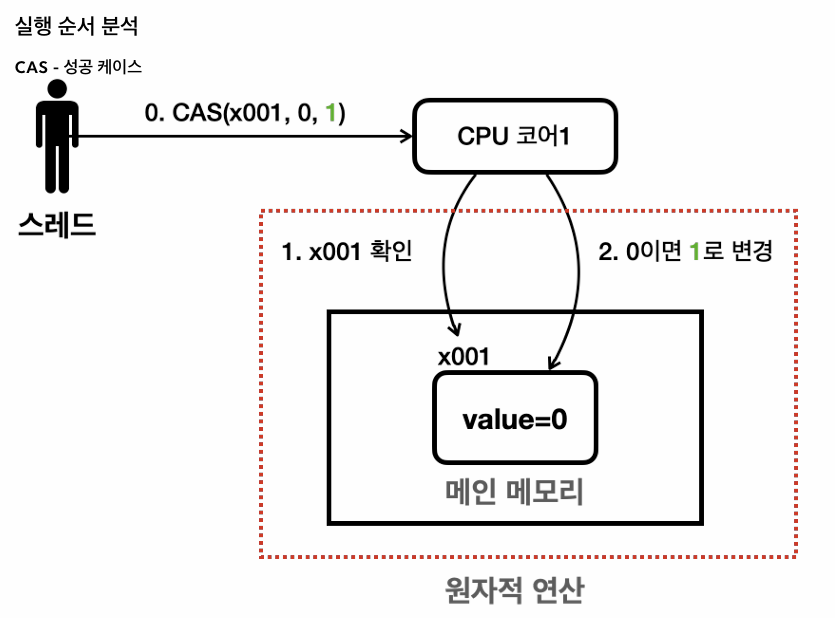
1. 기대하는 값을 확인하고 2. 값을 변경하는 두 연산을 하나로 묶어서 원자 적으로 제공한다는 것이다.
그렇다면 이것이 어떻게 LOCK의 일부분을 대체할 수 있을까?
public class CasMainV2 {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(0);
System.out.println("start value = " + atomicInteger.get());
// incrementAndGet 구현
int resultValue1 = incrementAndGet(atomicInteger);
System.out.println("resultValue1 = " + resultValue1);
int resultValue2 = incrementAndGet(atomicInteger);
System.out.println("resultValue2 = " + resultValue2);
}
private static int incrementAndGet(AtomicInteger atomicInteger) {
int getValue;
boolean result;
do {
getValue = atomicInteger.get();
log("getValue: " + getValue);
result = atomicInteger.compareAndSet(getValue, getValue + 1);
log("result: " + result);
} while (!result);
return getValue + 1;
}
}start value = 0
20:41:07.627 [ main] getValue: 0
20:41:07.629 [ main] result: true
resultValue1 = 1
20:41:07.630 [ main] getValue: 1
20:41:07.630 [ main] result: true
resultValue2 = 2
CAS 연산을 사용하면 여러 스레드가 같은 값을 사용하는 상황에서도 락을 걸지 않고, 안전하게 값을 증가할 수 있다. 여기서는 락을 걸지 않고 CAS 연산을 사용해서 값을 증가했다.
만약 CAS 연산이 성공한다면 true 반환하고 do- while을 빠져나온다.
만약 CAS 연산이 실패한다면 false 반환하고 do-while문을 다시 시작한다.
public class CasMainV3 {
private static final int THREAD_COUNT = 2;
public static void main(String[] args) throws InterruptedException {
AtomicInteger atomicInteger = new AtomicInteger(0);
System.out.println("start value = " + atomicInteger.get());
Runnable runnable = new Runnable() {
@Override
public void run() {
incrementAndGet(atomicInteger);
}
};
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < THREAD_COUNT; i++) {
Thread thread = new Thread(runnable);
threads.add(thread);
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
int result = atomicInteger.get();
System.out.println(atomicInteger.getClass().getSimpleName() + " resultValue: " + result);
}
private static int incrementAndGet(AtomicInteger atomicInteger) {
int getValue;
boolean result;
do {
getValue = atomicInteger.get();
sleep(100); // 스레드 동시 실행을 위한 대기
log("getValue: " + getValue);
result
= atomicInteger.compareAndSet(getValue, getValue + 1);
log("result: " + result);
}
while (!result);
return getValue + 1;
}
}
AtomicInteger 가 제공하는 incrementAndGet() 코드도 앞서 우리가 직접 작성한 incrementAndGet() 코드와 똑같이 CAS를 활용하도록 작성되어 있다. CAS를 사용하면 락을 사용하지 않지만, 대신에 다른 스레드가 값을 먼저 증가해서 문제가 발생하는 경우 루프를 돌며 재시도를 하는 방식을 사용한다.
이 방식은 다음과 같이 동작한다
- 현재 변수의 값을 읽어온다.
- 변수의 값을 1 증가시킬 때, 원래 값이 같은지 확인한다. (CAS 연산 사용)
- 동일하다면 증가된 값을 변수에 저장하고 종료한다.
- 동일하지 않다면 다른 스레드가 값을 중간에 변경한 것이므로, 다시 처음으로 돌아가 위 과정을 반복한다.
그러나 충돌이 빈번하게 발생하는 환경에서는 성능에 문제가 될 수 있다. 여러 스레드가 자주 동시에 동일한 변수의 값 을 변경하려고 시도할 때, CAS는 자주 실패하고 재시도해야 하므로 성능 저하가 발생할 수 있다. 이런 상황에서는 반복 문을 계속 돌기 때문에 CPU 자원을 많이 소모하게 된다. 사실 간단한 CPU 연산은 너무 빨리 처리되기 때문에 충돌이 자주 발생하지 않는다. 충돌이 발생하기도 전에 이미 연산을 완료하는 경우가 더 많다.
public class SpinLock {
private final AtomicBoolean lock = new AtomicBoolean(false);
public void lock() {
log("락 획득 시도");
while (!lock.compareAndSet(false, true)) {
// 락을 획득할 때 까지 스핀 대기(바쁜 대기) 한다.
log("락 획득 실패 - 스핀 대기");
}
log("락 획득 완료");
}
public void unlock() {
lock.set(false);
log("락 반납 완료");
}
}public class SpinLockMain {
public static void main(String[] args) {
SpinLock spinLock = new SpinLock();
Runnable task = new Runnable() {
@Override
public void run() {
spinLock.lock();
try {
// critical section
log("비즈니스 로직 실행");
//sleep(1); // 오래 걸리는 로직에서 스핀 락 사용X
} finally {
spinLock.unlock();
}
}
};
Thread t1 = new Thread(task, "Thread-1");
Thread t2 = new Thread(task, "Thread-2");
t1.start();
t2.start();
}
}
스핀 락
스레드가 락이 해제되기를 기다리면서 반복문을 통해 계속해서 확인하는 모습이 마치 제자리에서 회전(spin)하는 것처 럼 보인다. 그래서 이런 방식을 "스핀 락"이라고도 부른다. 그리고 이런 방식에서 스레드가 락을 획득 할 때 까지 대기하 는 것을 스핀 대기(spin-wait) 또는 CPU 자원을 계속 사용하면서 바쁘게 대기한다고 해서 바쁜 대기(busy-wait)라 한 다. 이런 스핀 락 방식은 아주 짧은 CPU 연산을 수행할 때 사용해야 효율적이다. 잘못 사용하면 오히려 CPU 자원을 더 많 이 사용할 수 있다. 정리하면 "스핀 락"이라는 용어는, 락을 획득하기 위해 자원을 소모하면서 반복적으로 확인(스핀)하는 락 메커니즘을 의 미한다. 그리고 이런 스핀 락은 CAS를 사용해서 구현할 수 있다.